
Kubernetes 已然成为事实上的容器编排标准,是运维、开发人员使用最流行的微服务、DevOps、CI/CD 云原生底座。本文重演了Kubernetes 的起源故事,介绍了 Kubernetes 的重要知识点,最后列出了 DaoCloud 道客开源团队近一年来做出的显著贡献。
谈到 Kubernetes,就绕不开 Docker。
2010 年几个搞 IT 的年轻人在旧金山使用谷歌 go 语言开发了一个创建和管理容器的工具供公司内部使用,命名为 Docker。其寓意是用 Docker 这艘船承载 container(集装箱)以封装和支撑各类应用服务。
这一阶段 Docker 是一个闭源工具,其技术仅限于企业内部使用,没有引起 IT 行业的任何关注。当时 Docker 所在的公司在激烈的市场竞争下步履维艰。
2013 年 3 月公司就要坚持不下去了,以 Solomon Hykes 为首的技术团队沮丧之余,不忍让 Docker 这样的前沿容器技术付之东流,抱着破罐子破摔试一试的心态,将 Docker 在 GitHub 社区上彻底开源。开源之时使用的一句宣传标语是“Build Once, Run Everywhere”,即“一次构建,随处运行”。
万万没想到,不开则已,一开惊人。这就像打开了容器领域的潘多拉魔盒,越来越多的 IT 工程师发现了 Docker 的优点,大家蜂拥而至加入 Docker 开源社区学习并作出贡献。Docker 人气迅速攀升,所在公司迅速起死回生,这项技术的传播速度之快,令早就在使用和推广容器等 IT 基础设施技术的 Google 等互联网国际大厂瞠目结舌。
随着 Docker 在容器技术开源社区站稳脚跟,并在多个场合和商业应用场景挑战了 Google 的切身利益。Google 管理层深感不妙,在 Docker 项目刚兴起的同一年就迅速祭出一剑:将内部生产验证的容器栈管理工具 MCTFY (Let Me Container That For You) 开源。另一方面,Google 还有意支持 Docker 的多个竞争对手和项目发展,但事与愿违,面对 Docker 的强势崛起和渗透,Google 的这些举措表现得毫无招架之力。
战局节节败退,Google 作为财力雄厚的互联网财阀,直接开出高价有意买断 Docker。但 Docker 的技术总监兼联合创始人 Solomon Hykes 估计是一位理想主义者,雄心万丈的他对抛来的这枚橄榄枝不屑一顾。技术牛人就是这么率真、耿直!
容器战场的连番失利和收购意图被漠视,促使 Google 高层改变策略,2014 年6 月在开源社区放出了内部雪藏近十年的底层核心技术,即大规模集群管理系统 Borg,这就是 Kubernetes 的前身。
IT 江湖,技术为先。如同当年 Docker 横空出世一样,Kubernetes 再一次改写了容器市场的格局。2015 年 7 月 Kubernetes 1.0 正式发布。同年 Google 宣布成立 CNCF,全称 Cloud Native Computing Foundation(云原生计算基金会),建立以 Kubernetes 为中心的云原生解决方案开放生态体系。
2017 年 Docker 将容器运行时部分 Containerd 捐献给 CNCF 社区,同年 10 月又宣布将 Docker 企业版内置到 Kubernetes 项目,持续了几年的容器编排之争终于落下帷幕。
Kubernetes 一词来源于希腊语,意思是“舵手”或“领航员”,起初这一命名也有针对 Docker(码头搬运工)的意味。许多从业者经常将 Kubernetes 称为 k8s,这是因为 Kubernetes 这个单词太长,发音绕口又不容易记,而首字母 k 和尾字母 s 之间有 8 个字母,所以也就简写成了 k8s。
Kubernetes 是大规模集群管理系统 Borg 的开源版本,经过 Google 内部十多年的实践生产检验,一经推出就在整个社区推进“民主化”架构,即从 API 到容器运行时的每一层,Kubernetes 项目都为开发者暴露出了可扩展的插件机制,鼓励全球开发者和用户通过代码的方式介入 Kubernetes 项目的每一个阶段。
在这种鼓励创新的整体氛围中,Kubernetes 社区在 2016 年之后得到了空前发展。不再局限于单个应用的打包、发布,这次容器社区的繁荣,是一次完全以 Kubernetes 各层级项目为核心的“百家争鸣”。
下图为2019 年9 月 CNCF 发布的以Kubernetes 为中心建立的云原生生态体系全景图。从图中可以看出,Docker 只是其中一个不易发现的组件。
https://l.cncf.io (二维码自动识别)
迄今为止,CNCF 全景图中的技术卡片数量已达到 965 张,数以千计的新兴技术在开源社区蓬勃发展,市场总估值超 16 万亿美元。有兴趣的同学可以查阅 CNCF Landscape 交互式全景图。
第一次看到 $16.1T 这样的金额,小编几乎怀疑自己看错了,反复确认才明白这一天文数字般的市值是时下正在发生的既成事实:开源即是未来,而未来已来。
在如此规模的开源生态面前,最近频上热搜、饱受争议的 BAT 也许只是个刚起步的菜鸟。闲话不多说,接下来探讨是什么样的技术造就了如此规模的生态。
k8s 的编排体系如同一个大型企业的组织架构,集群是各个职能部门,一个集群主要由 Master、Node 两部分组成。其中 Master 是部门管理层,Node 就是干活儿的打工仔,而这些 Node 上处理的 Pod 就是一个个细小的碎片化任务。
优秀的管理层 Master 不但能把自己所在集群管理得井井有条,对于跨集群的项目任务,处理起来也游刃有余,这就是跨集群管理。
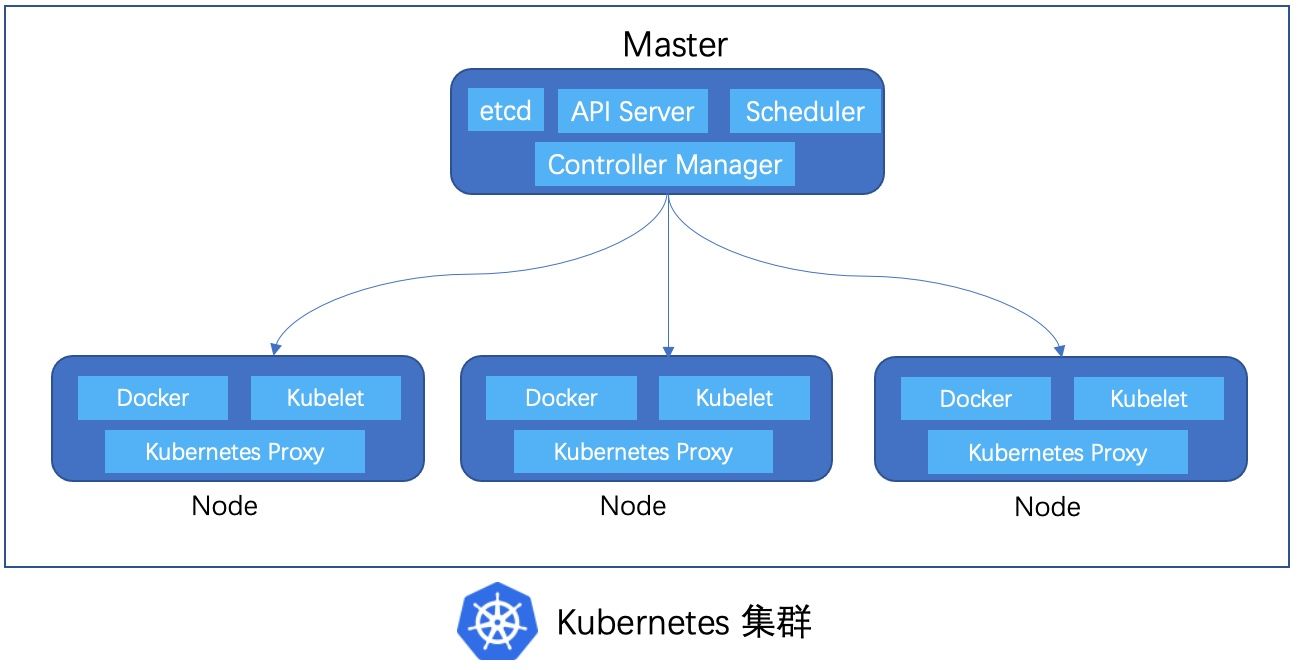
作为管理层的 Master 由各个领域的精英组成,首先是四大管理进程:
一个集群除了上述四大进程组成的管理层之外,还需要切实干活儿的底层员工,这就是 Node 上运行的进程。它们为了生存糊口,各司其职,兢兢业业地尽忠职守:
Kubernetes 的本质是一组服务器集群管理体系,它可以在集群的每个节点上运行特定的进程,来对节点中的容器进行管理。目的是实现资源管理的自动化,主要提供了如下的主要功能:
接下来我们讲解 Kubernetes 常用的操作资源对象:Pod、Service 和存储。
使用 Docker 时,若在一台主机上创建两个容器 A、B,容器之间通过Namespace 进行隔离,容器 A、B 都有自己的网络空间、IP 地址等等。如果容器 A 和 B 之间需要交换数据,Docker 允许我们将容器端口暴露给主机,通过端口映射到主机让两个容器进行通讯,当然也可以通过共享网络栈等方式进行容器之间的通讯。
但这些配置比较繁琐,从另一个角度考虑,有些容器就应该在一起,并且它们之间应该能够见面,也就是通过 localhost 的方式互相访问。但是如果采用标准容器方案无法实现,除非把两个不同的进程封装到同一个容器中,或者是容器 A 采用容器 B 的网络栈,但是这样会存在安全方面的隐患,因此,Kubernetes 提出了一个新的概念,叫做 Pod。
那么 Pod 是如何解决上述问题的呢?如下图所示:
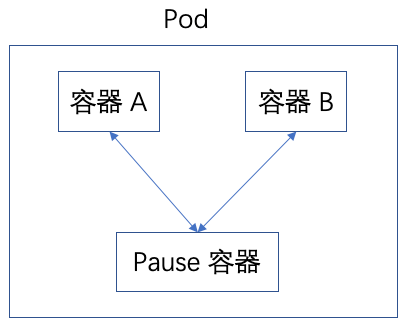
从上图可以,Pod 包含一个或多个容器,所以 Pod 有时也称为容器组,是 Kubernetes 资源管理的最小单位。每个 Pod 可以包含上图的容器 A、B,以及一个特殊的 Pause 容器。Pause 容器是 Pod 启动时第一个启动的容器,其他容器共享 Pause 容器的网络栈和 Volume 挂载卷。
Kubernetes 提供了多种部署 Pod 的方式,主要分为两种:
| 控制器名称 | 描述 |
|---|---|
| Replication Controller (RC) | 用于确保容器应用的副本数始终保持在用户定义的副本数,即如果有容器异常退出,会自动创建新的Pod来代替;而异常多出来的容器也会自动回收。 |
| ReplicaSet | 与 RC 类似,支持支持集合式的 Selector。API 和 Kind 类型与 RC 不同: apiVersion: extensions/v1beat1 Kind: ReplicaSet |
| Deployement | 为 Pod 和 RS 提供了一个声明式定义方法,用来替代以前的 RC,方便管理应用,提供了 Pod 的滚动升级和回滚特性。 |
| Horizontal Pod Autoscaling (HPA) | 是一种资源对象,支持 Pod 自动横向扩容。实现原理为:通过追踪分析所有控制 Pod 的负载变化情况,来确定是否需要针对性地调整目标 Pod 的副本数。 |
| StatefulSet | 解决有状态服务的问题(相对于无状态的 Deployement 和 ReplicaSet),其应用场景包括稳定的持久化存储、稳定的网络标志、有序部署、有序扩展和有序收缩等。 |
| DaemonSet | 确保全部或部分 Node 上运行一个 Pod 副本。当有 Node 加入集群时,也会为新 Node 创建一个新的 Pod。当有 Node 从集群移除时,回收 Pod。删除 DaemonSet 将删除它所创建的所有 Pod。 |
| Job | 负责批处理任务,即仅执行一次的任务,它确保批处理任务的一个或者多个 Pod 成功运行。 |
| CronJob | 管理基于时间的Job,即: l 在指定时间点只运行一次。 l 周期性地在给定时间点运行。 |
假设 Kubernetes 集群中运行了好多 Pod,Kubernetes 在创建每个 Pod 时会为每个 Pod 分配一个虚拟的 Pod IP 地址,Pod IP 是一个虚拟的二层网络地址。
集群之间不同机器之间 Pod 的通讯,其真实的 TCP/IP 流量是通过Node 节点所在的物理网卡流出的(Node IP)。由于Pod IP 是 Kubernetes 集群内部的一些私有 IP 地址,因此 Kubernetes 集群内部的程序才可以访问 Pod,Kubernetes 集群之外的程序没有办法访问。
然而我们部署的许多应用都需要提供给外部客户端访问,因此,可以通过kubernetes 的服务发现(Service)将这些服务暴露给客户端,然后客户端就可以通过 IP+Port 的方式访问多个 Pod。
为什么说是多个 Pod 呢?因为 Service 为我们提供了复杂的均衡机制。例如我们通过 Deployment 部署了一个 Tomcat,replicas 设置为 3,Service 提供了多种负载均衡策略,针对不同的请求路由到不同的 Pod 上。如下图所示。
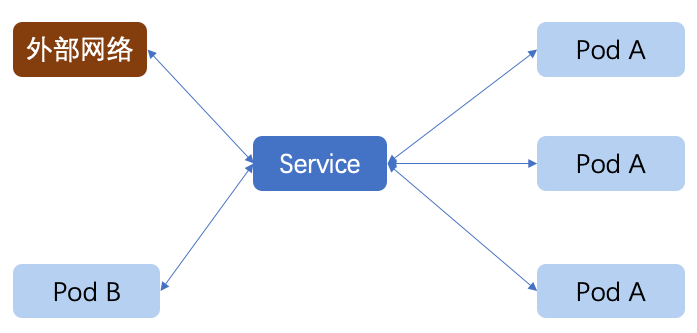
采用微服务架构时,作为服务所有者,除了实现业务逻辑外,我们也需要考虑应该怎样发布服务,例如发布的服务中哪些服务不需要暴露给客户端,仅仅在服务内部之间使用,哪些服务又需要暴露出去,因此,Kubernetes 提供了多种灵活的服务发布方式,主要包括:ClusterIP、NodePort、LoadBalancer等,其关系如下图所示。
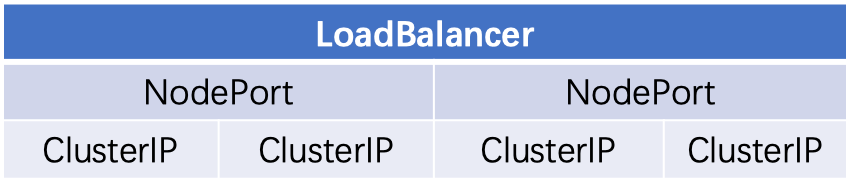
当发布服务时,Kubernetes 会为服务默认分配一个虚拟的 IP,即 ClusterIP,这也是 Service 默认的类型。ClusterIP 更像是一个“伪造”的IP 网络,原因有以下几点:
根据上述的分析和总结,我们知道 Service 的ClusterIP 属于 Kubernetes 集群内部的地址,无法在集群外部直接使用这个地址。
那么矛盾来了,实际上平常开发的许多业务肯定有一部分服务是要提供给Kubernetes 集群外部的应用或者让用户来访问的,典型的就是 Web 端的服务模块,因此在发布这些 Service 时,可以采用 NodePort 的方式。
但 NodePort 还没有完全解决外部访问 Service 的所有问题,比如负载均衡问题,假如我们的集群中有 10 个 Node,则此时最好设一个负载均衡器,外部的请求只需访问此负载均衡器的 IP 地址,由负载均衡器负责转发流量到后面某个 Node 的 NodePort 上,如下图所示。
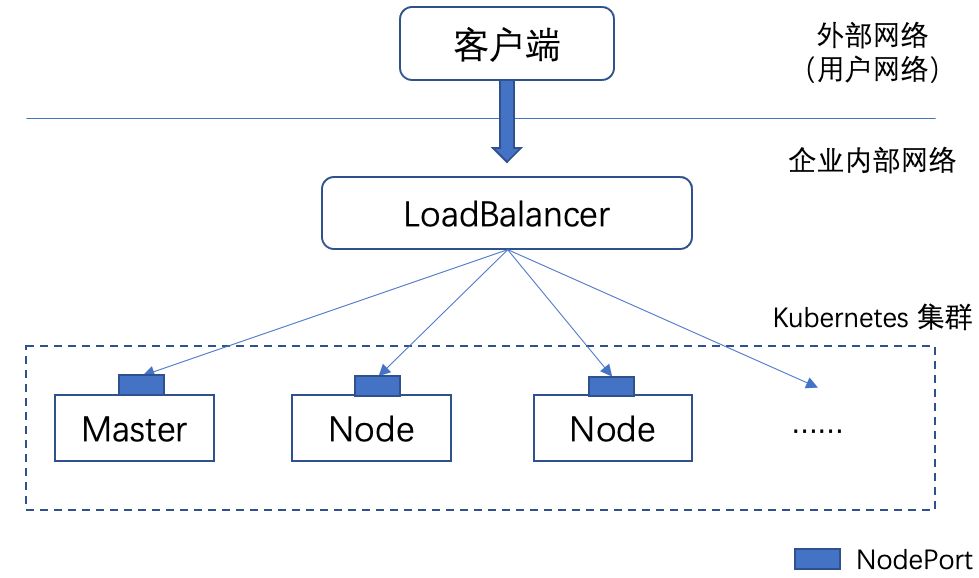
上图中的 LoadBalancer 组件独立于 Kubernetes 集群之外,通常是一个硬件的负载均衡器,或者是以软件方式实现的,例如 HAProxy 或者 Nginx。
对于每个 Service,我们通常需要一个对应的 LoadBalancer 实例来转发流量到后端的 Node 上,这的确增加了工作量和出错的概率。
于是 Kubernetes 提出了自动化的方案,如果集群运行在公有云上,那么只要把 Service 的 type=NodePort 改成 Node=LoadBalancer,此时Kubernetes 会自动创建一个对应的 LoadBalancer 实例并返回它的 IP 地址供外部客户端使用。
对于服务,我们经常将其分为两大类:有状态服务、无状态服务。
有状态服务常见的例如调度器、Apache 等。对于 Docker 来说,其更适应于无状态服务,但是 Kubernetes 的目标是作为未来基础设施的平台,其必须要攻克有状态服务,那有状态服务有些数据需要持久化,需要保存起来。因此Kubernetes 引入了多种存储:
ConfigMap 功能在 Kubernetes 1.2 版本中引入,许多应用程序会从配置文件、命令行参数或者环境变量中读取配置信息。
ConfigMap API 提供了向容器中注入配置信息的机制,ConfigMap 可以用来保存单个属性,也可以保存整个配置文件或者 JSON 二进制对象。
Secret 解决了密码、token、密钥等敏感数据的配置,而不需要把这些敏感数据暴露到镜像或者 Pod Spec 中。
Secret 可以作为 Volume 或者环境变量的方式使用。
Secret 有三种类型:
容器磁盘上的文件生命周期是短暂的,这就使得在容器中运行重要应用时会出现一些问题。
首先,当容器崩溃时,Kubelet 会重启它,但是容器中的文件将丢失,因为容器会以干净的状态(镜像最初的状态)重新启动。
其次,在 Pod 中同时运行多个容器时,这些容器之间通常需要共享文件。Kubernetes 中的 Volume 抽象就很好地解决了这些问题。目前,Kubernetes支持多种类型的 Volume,例如 GlusterFs、Ceph 等先进的分布式文件系统。
Volume 的使用也比较简单,在大多数情况下,我们先在 Pod 上声明一个Volume,然后在容器里引用该 Volume 并 Mount 到容器里的某个目录上即可。
之前我们提到的 Volume 是定义在 Pod 上的,属于“计算资源”的一部分,而实际上,“网络存储”是相对独立于“计算资源”而存在的一种实体资源。
比如在使用虚拟机的情况下,我们通常会先定义一个网络存储,然后从中划出一个“网盘”并挂在到虚拟机上。Persistent Volume(简称 PV)和与之关联的Persistent Volume Clain(简称 PVC)也起到了类似的作用。
PV 可以理解成 Kubernetes 集群中某个网络存储对应的一块存储,它与Volume 很类似,但有以下区别:
了解了上述资源对象后,我们接下来就是如何操作这些对象。
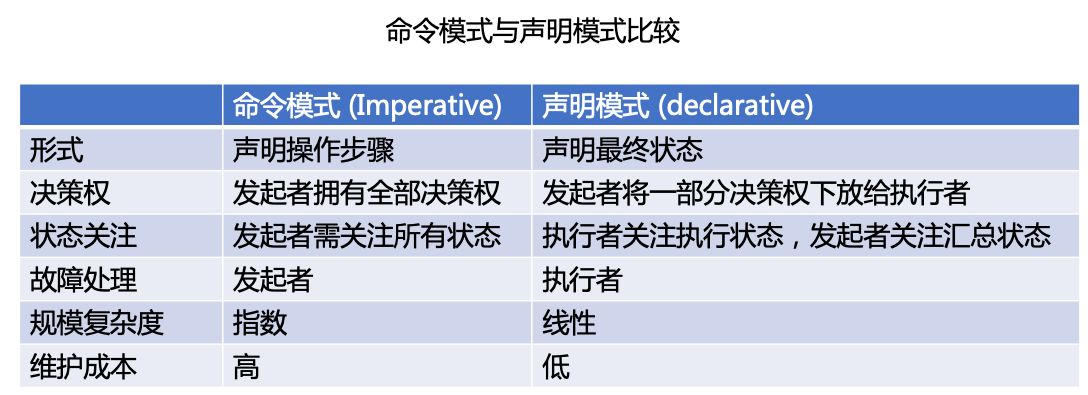
命令模式和声明模式是 Kubernetes 操作资源对象的一个重要基础,只有先了解了它们之间的区别才能理解我们为什么要用声明的方式来创建资源。
举例来说,假设要完成一个任务,这个任务是要运行 5 个 nginx 副本,在命令模式下需要运行 5 次 docker run,生成 5 个相同的副本,简言之,命令模式要求对方完全按照特定的指示来做,它自己没有任何自主的想法。
而声明模式把以上所有步骤全部省掉,直接把需要做的事情在一个文件里声明,在文件里设置一个参数,最终运行 5 个 Nginx 副本。

那么问题来了,如果在运行这 5 个 Nginx 副本中间发生了错误,会出现什么样的情况呢?
对于命令模式来说,会产生不可预期的后果,又或者需要额外的干预,比如之前的命令发生了错误,只运行了 3 个副本,我们必须查看一下之前的命令是成功还是失败、有几个副本运行。如果之前运行了 3 个,那我们还需要再发出 2 次命令,运行 2 次。
但是在声明模式下,我们把任务交代给谁,谁就负责来查看现在到底有几个副本,如果运行的副本数量不是 5 个,它就会一直试图去恢复 5 个副本,直至成功。
那如果这个命令重复运行了 2 次,情况又如何?
对于命令模式来说,如果运行 2 次,就会产生 2 倍的副本;而如果声明模式运行了 2 次,因为声明的是一件事情,除非第二次修改了命令,否则只要命令是一样的,那么就只会生成 5 个副本,副本数量不会增加。这也是命令模式和声明模式最关键的区别所在。
命令模式要求我们交代操作步骤,而在声明模式只需要描述最终状态。具体来说,在命令模式下,决策权掌握在发起命令的人手里;而在声明模式下,只需要把决策权下发给执行者,由执行者来关注如何运行、如何达到所需要的状态。
在故障处理方面,命令模式需要发起者处理所有的故障,所以它的复杂度是随着关注对象的多少呈指数增长的。而声明模式下,执行者只需要关注汇总状态,所以它的复杂度是线性的,维护成本相对命令来说要低得多。也因此声明模式更适合大规模应用,这也是 Kubernetes 使用声明模式的根源所在,即便它也支持命令模式。
以上讲述了一些 Kubernetes 的通用知识点,因篇幅有限,如需了解更多信息,请参阅 Kubernetes 文档。
DaoCloud 早在 2014 年就敏锐地发现容器、Docker 和 Kubernetes 的巨大发展潜力。k8s 第一个非正式版发布之际,时任 EMC 总架构师的陈齐彦与 EMC 研究院高级研究员颜开就多次热烈探讨容器技术的未来前景。双方一拍即合,这也就有了致力于云原生技术创新的 DaoCloud 道客网络科技。
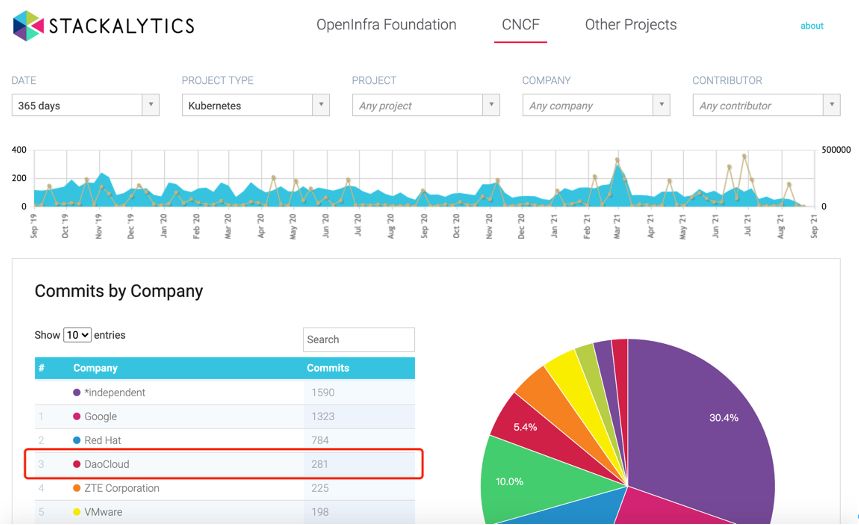
据 Stackalytics 数据统计,过去 365 天内 DaoCloud 开源团队在 Kubernetes 开源社区的贡献数排名全球前 3,中国第 1。
 AI助手
AI助手 资讯
资讯 常用工具
常用工具 网站模板
网站模板